|
To enable progress towards egocentric agents capable of understanding everyday tasks specified in natural language, we propose a benchmark
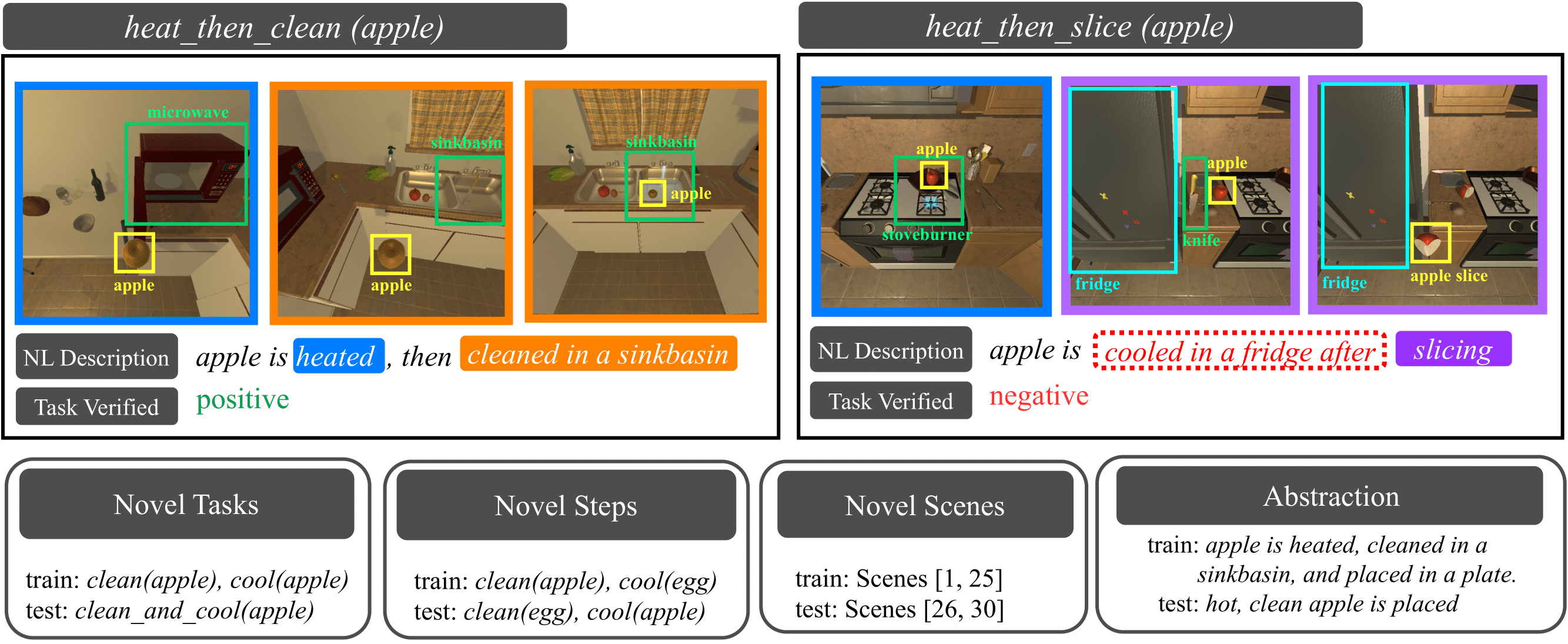
and a synthetic dataset called Egocentric Task Verification (EgoTV). The goal in EgoTV is to verify the execution of tasks from egocentric
videos based on the natural language description of these tasks. EgoTV contains pairs of videos and their task descriptions for multi-step
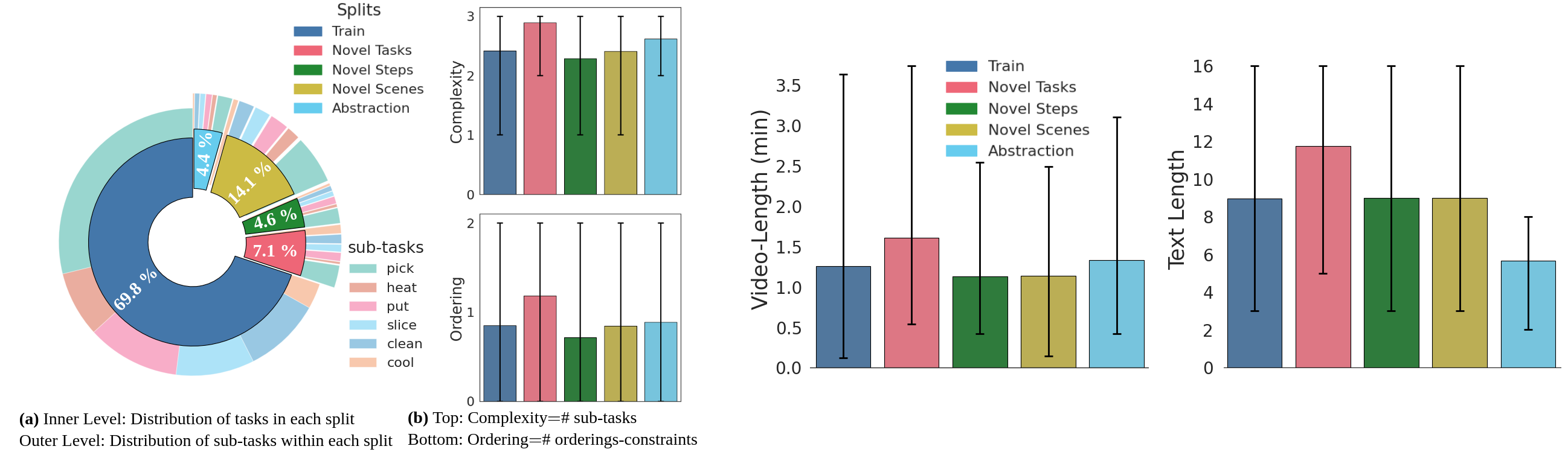
tasks -- these tasks contain multiple sub-task decompositions, state changes, object interactions, and sub-task ordering constraints. In
addition, EgoTV also provides abstracted task descriptions that contain only partial details about ways to accomplish a task.
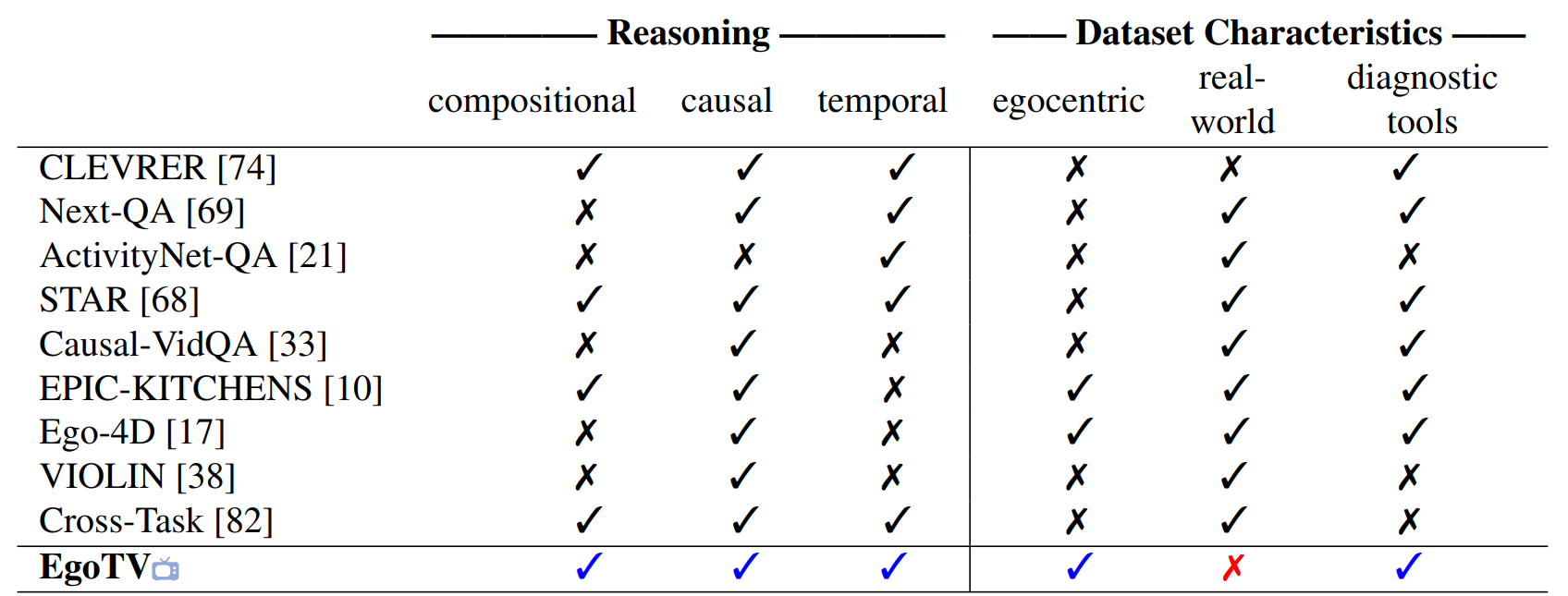
Consequently, EgoTV requires causal, temporal, and compositional reasoning of video and language modalities, which is missing in existing
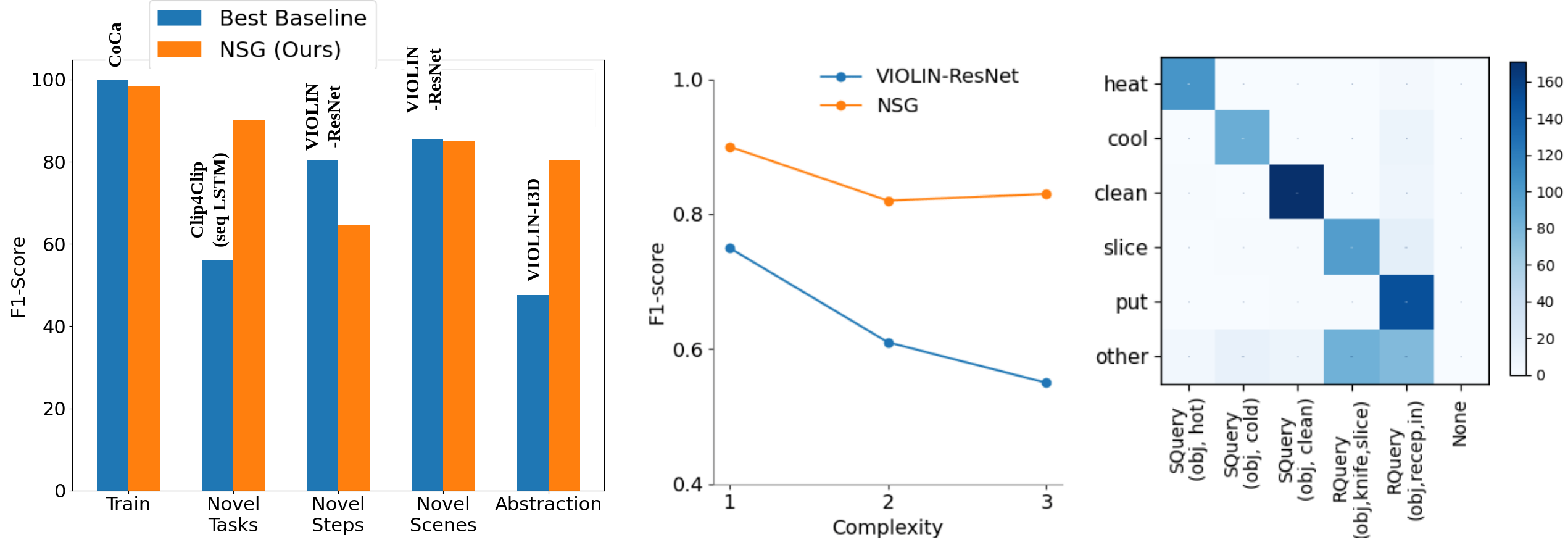
datasets. We also find that existing vision-language models struggle at such all round reasoning needed for task verification in EgoTV.
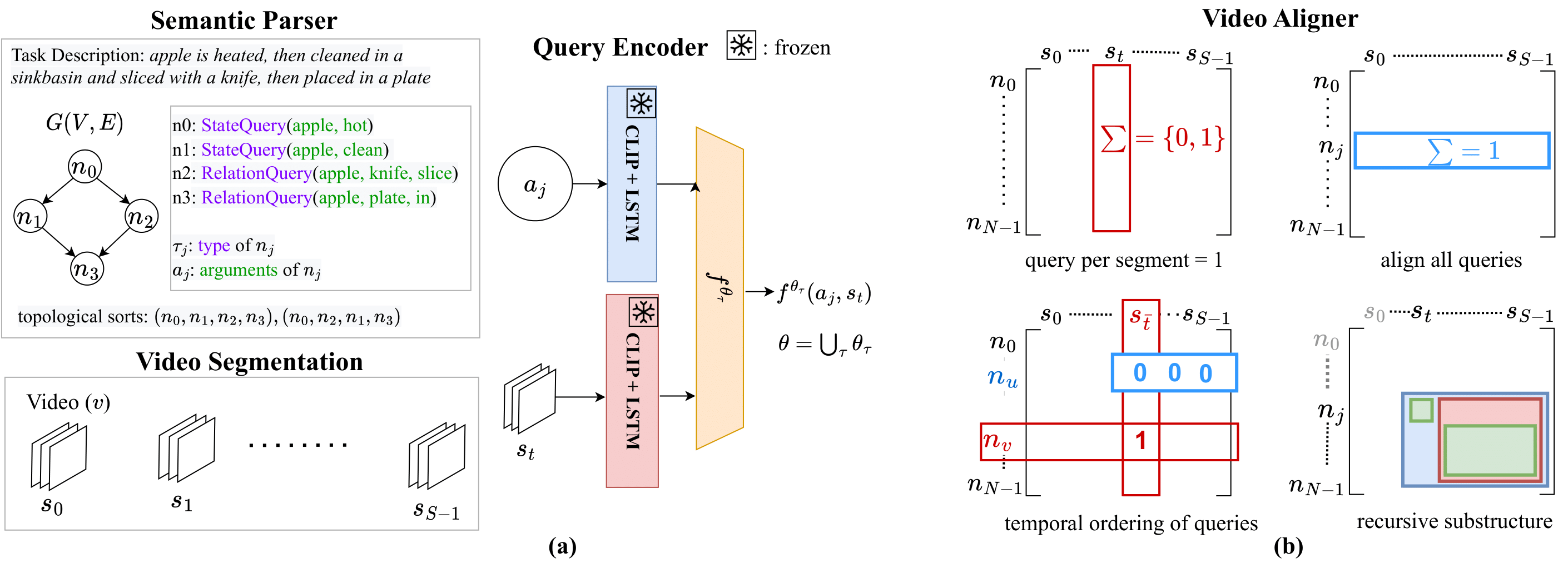
Inspired by the needs of EgoTV, we propose a novel Neuro-Symbolic Grounding (NSG) approach that leverages symbolic representations to
capture the compositional and temporal structure of tasks. We demonstrate NSG's capability towards task tracking and verification on our
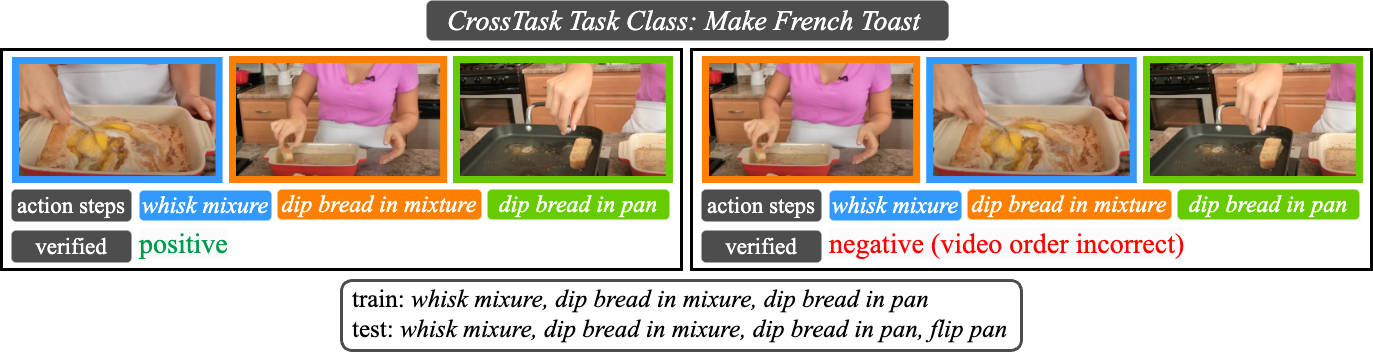
EgoTV dataset and a real-world dataset derived from CrossTask (CTV). We open-source the EgoTV and CTV datasets and the NSG model for
future research on egocentric assistive agents.
|
 : Egocentric Task Verification from Natural Language Task
Descriptions
: Egocentric Task Verification from Natural Language Task
Descriptions