
| AAAI 2024 |
| Rishi Hazra1 | Pedro Zuidberg Dos Martires1 | Luc De Raedt12 |
| Örebro University1 | KU Leuven2 |
| arXiv | AAAI | Video | Robot | GitHub |
Large Language Models (LLMs) have demonstrated impressive planning abilities due to their vast "world knowledge". Yet, obtaining plans that are both feasible and cost-effective (in length), remains a challenge, despite recent progress. This contrasts with heuristic planning methods that employ domain knowledge (formalized in action models such as PDDL) and heuristic search to generate feasible, optimal plans. Inspired by this, we propose to combine the power of LLMs and heuristic planning by leveraging the world knowledge of LLMs and the principles of heuristic search. Our approach, SayCanPay, employs LLMs to generate actions (Say) guided by learnable domain knowledge, that evaluates actions' feasibility (Can) and long-term reward/payoff (Pay), and heuristic search to select the best sequence of actions.
Large Language Models are imperfect planners. We propose to combine System 1 (Classical Planning) and System 2 (LLM Planning) into a single LLM Planning framework.

We formulate LLM Planning in the context of heuristic planning via the given POMDP formulation. ⟨ S, SG, b0int, A, O, R, 𝒯int ⟩ Previous works have shown that language models (LMs) trained on extensive data would internalize rich world knowledge that can be queried for downstream tasks like planning. This is akin to an internal transition function. Similarly, LMs also maintain and update an internal belief state over tokens (or actions).
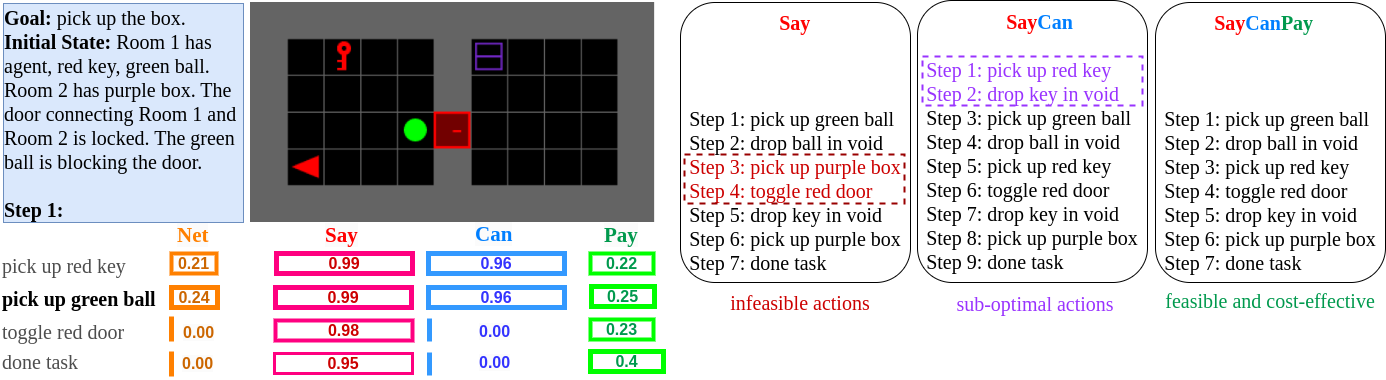
We incorporate feasibility and cost-effective elements into the generated plans using a joint scoring named SayCanPay. As depicted in Figure 1, it directs the planning through three key steps:
The Can and Pay models undergo domain-specific training to align the plans with the current environment.
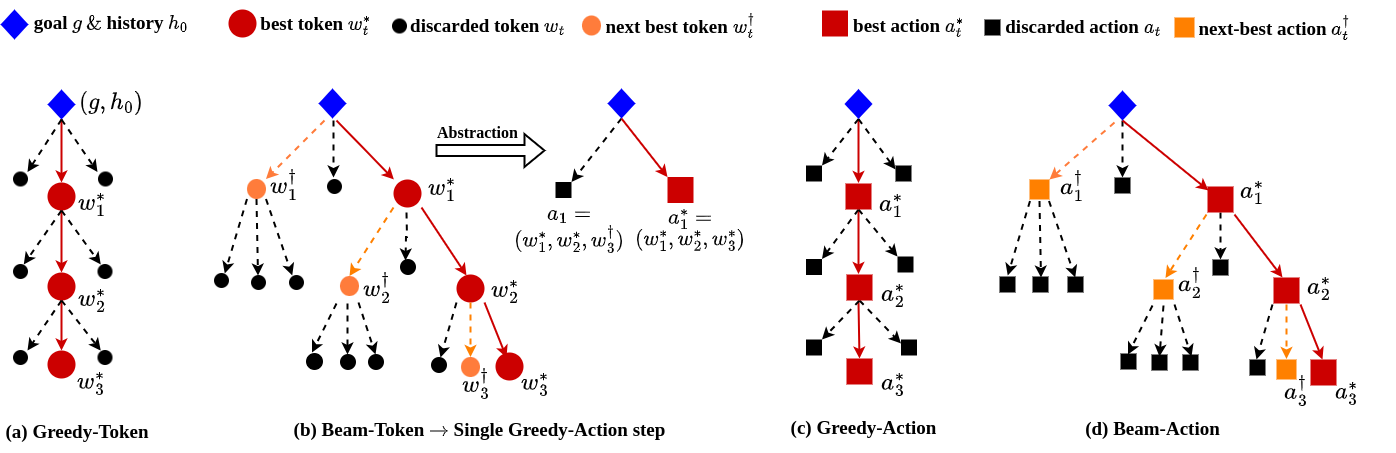
We propose a tree-search over action space using the aggregate SayCanPay scores.
The Greedy-Token and Greedy-Action decoding is used by most existing planning frameworks.
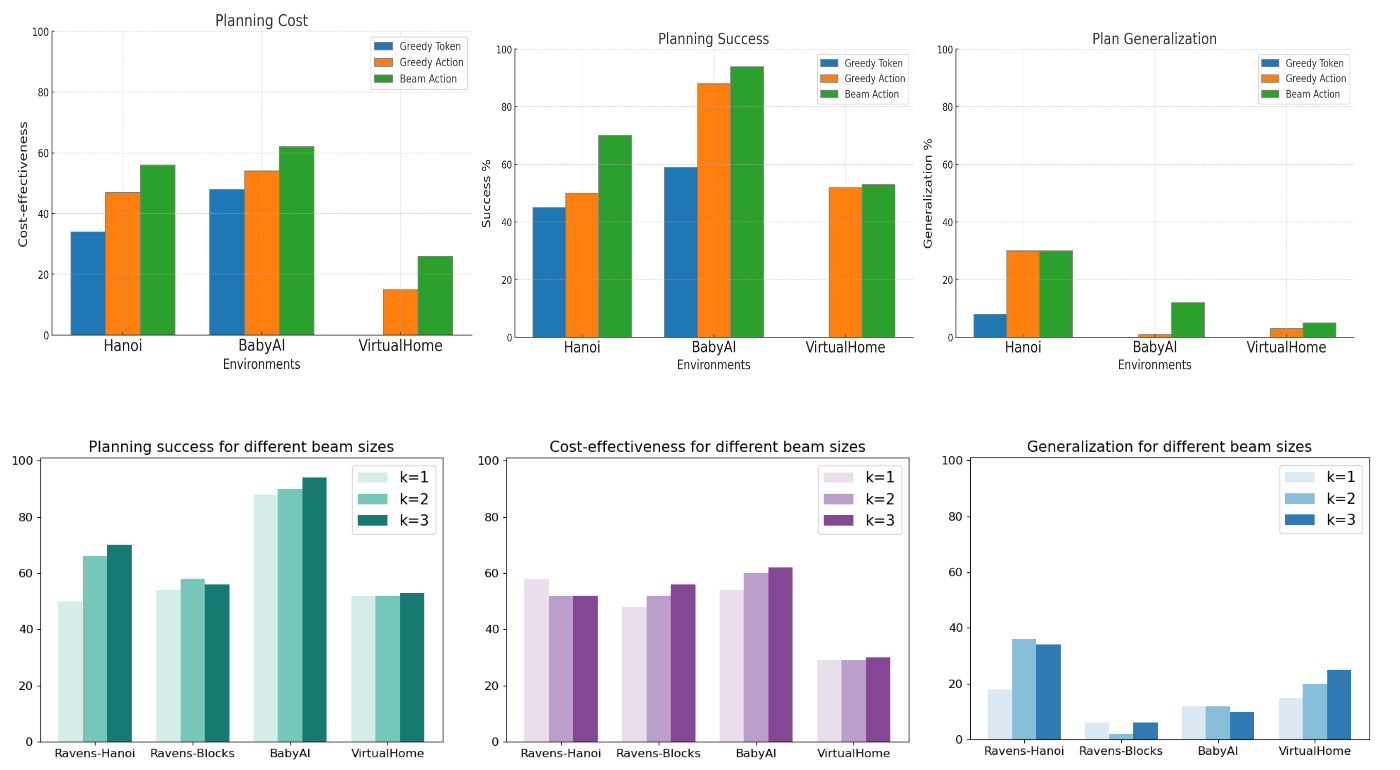
Using this aggregate score for heuristic search, we generate the most feasible and cost-efficient plan. We exhibit how our proposed joint scoring and heuristic search outperform existing LLM planning paradigms.
 |
R. Hazra, P Zuidberg Dos Martires, L De Raedt SayCanPay: Heuristic Planning with Large Language Models using Learnable Domain Knowledge arXiv, 2023. [Bibtex] |